
摘要:在异构卫星网络动态组网时,为了解决星上软件通信适配器对物理层调制模式识别率低的问题,提出了一种适合低信噪比和贫先验知识的自动调制模式识别算法.该算法以高斯白噪声信道作为信道模型,选取信号高阶累积量和经典统计量作为特征参数,采用引力搜索算法对径向基神经网络基函数中心进行优化,并在引力搜索算法中引入粒子群的信息熵来调节算法执行过程中探索与开采的关系,进一步提高了算法的分类和泛化能力.然后,利用仿真试验测评了该算法对6种卫星常用调相调制信号的识别效果.仿真试验结果表明,没有先验知识的情况下,该算法在调制信号信噪比大于4 dB时就可以达到100%的识别率,从而证明了该算法在低信噪比和贫先验知识条件下的有效性,说明算法满足星上软件通信适配器对物理层调制模式的识别要求.
关键词:异构卫星网络;软件通信适配器;自动调制模式识别;高阶累积量;信息熵
在异构卫星网络动态组网的问题中,通过搭载于星上的软件定义通信适配器(SDCA)对可能进行组网的卫星的物理层通信参数进行自动识别,是解决物理层参数获取与感知的关键.自动调制模式识别(AMC)方法层出不穷[1].其中,基于统计模式的识别方法理论分析简单,算法复杂度低,所需先验知识少,特别适合星上应用,但需要选择合适的特征参数和设计泛化能力强的分类器.由于高斯白噪声的二阶以上累积量为零,故高阶累积量具有良好的抗高斯噪声的能力[2],径向基函数神经网络(RBFNN)结构简单、训练时间短,适合于解决分类问题.目前,已有学者利用信号的高阶统计量和RBF神经网络对调制模式识别进行研究,并取得了一定的研究成果[3].RBFNN隐含层基函数中心的选择对其分类能力有很大影响,需要对其基函数中心进行优化.引力搜索算法是一种基于牛顿万有引力定律的启发式优化算法,该算法的收敛性明显优于粒子群算法(PSO)、遗传算法(GA)等其他智能优化算法[4].信息熵是信息量的度量,通过引入信息熵来度量引力搜索算法中粒子群的信息量,可以反映出算法迭代过程中探索与开采的关系,调节算法的执行过程,进而提高算法性能.
结合卫星常用调相信号和卫星平台计算能力的特点,本文选用信号的高阶统计量和经典统计量作为特征参数,采用基于信息熵改进的GSA算法来优化RBF神经网络基函数中心.将优化后的RBF神经网络作为分类器,对BPSK,QPSK,8PSK,16QAM,32QAM和64QAM等6种卫星常用调相调制信号进行识别分类,并通过计算机仿真验证了所提算法的有效性和可行性.
1 星上软件通信适配器
星上软件通信适配器是解决异构卫星网络动态组网问题的关键.SDCA采用软件定义的方法,形式化描述卫星组网所需的底层参数,向上提供了获取数据和参数的接口.同时,SDCA需要对物理层参数进行感知与获取,才能根据需求动态地调整卫星的通信参数,屏蔽不同类型卫星的通信体制区别,向下提供进行通信适配所需的接口映射机制.该模型如图1所示.
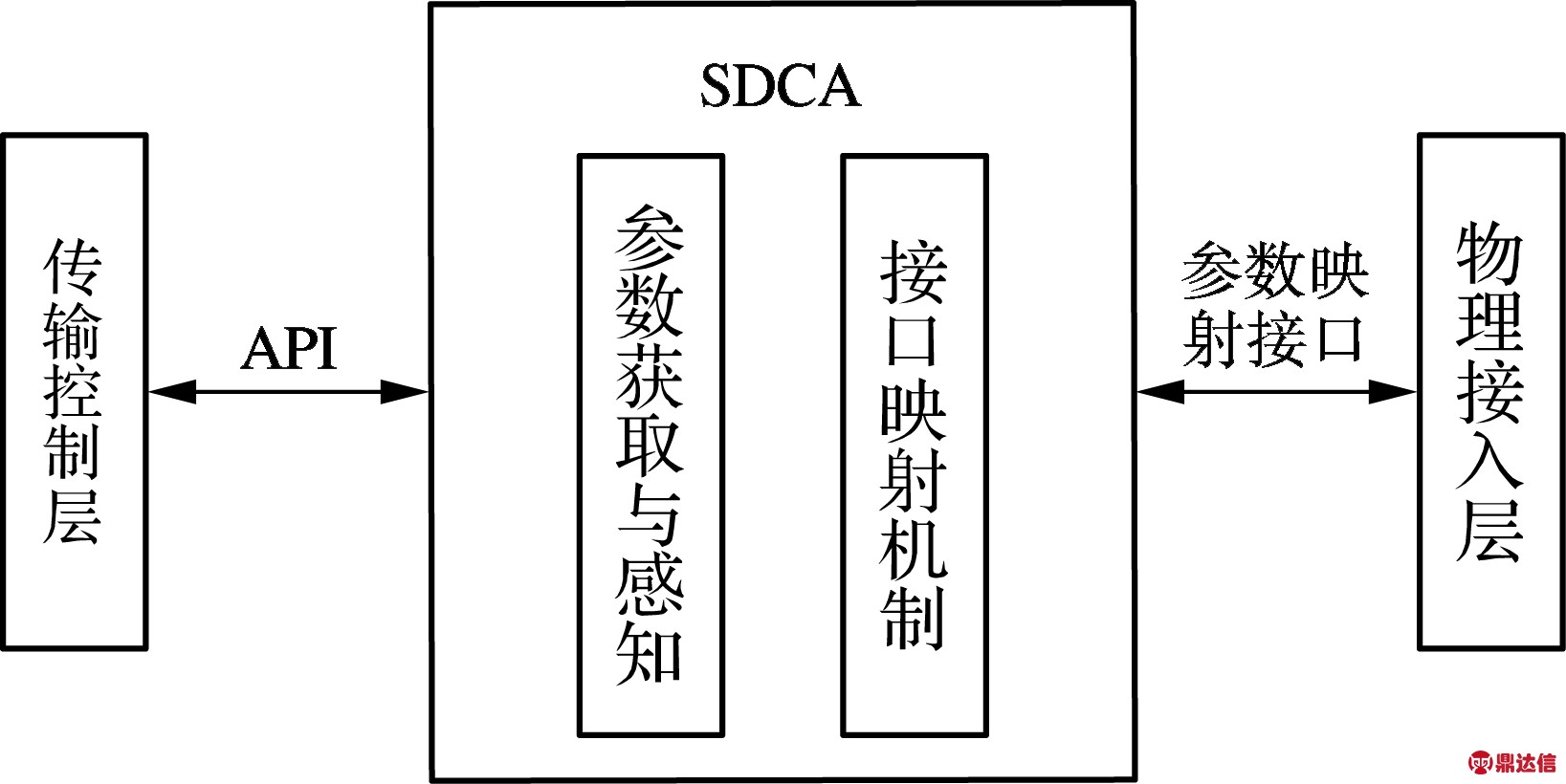
图1 SDCA模型示意图
根据数字通信的基本模型,SDCA需要获取与感知的物理层参数可以定义为如下的九元组:
〈F,M,P,Mu,B,SCo,CCo,Cp,Ca〉
(1)
式中,F为工作频率;M为调制方式;P为极化方式;Mu为信号复用方式;B为传输速率;SCo为信源编码方式;CCo为信道编码方式;Cp为通信协议;Ca为信道分配方式.
2 信号模型
本文对卫星常用的6种调相调制信号BPSK,QPSK,8PSK,16QAM,32QAM和64QAM进行分类,考虑均值为零、方差为![]() 的高斯白噪声(AWGN)信道模型.对于经过数字调相方式调制后的发射信号和噪声信号,接收机接收到的信号r(t)可表示为
的高斯白噪声(AWGN)信道模型.对于经过数字调相方式调制后的发射信号和噪声信号,接收机接收到的信号r(t)可表示为
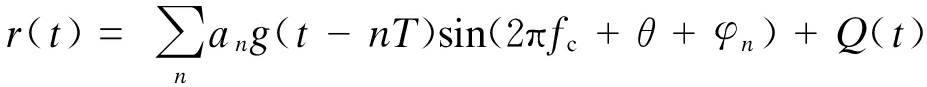
(2)
式中,an(n=1,2,…,N)为码元幅度;fc和θ分别为载波的频率和相位;φn为调制相位;g(t-nT) 为加窗函数,本文设为升余弦窗;Q(t)为零均值高斯白噪声.
3 特征选取
基于统计模式识别的方法很大程度上依赖于信号特征的选取.目前,常用的信号统计特征主要分为经典统计特征、高阶统计特征、周期平稳特征和多重分形特征4类.表1列出了上述特征对于自动调制识别的影响[5].
表1 不同统计特征对AMC的影响
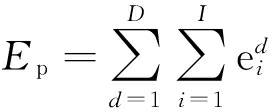
然而,针对星上SDCA的调制识别来说,不仅需要考虑信号特征对调制方式的识别能力和对信道噪声的抑制能力,还需要考虑星上的实际处理能力.因此,本文在进行特征选取时综合考虑了特征值的复杂度和有效性,选取了信号的经典统计特征和高阶统计特征.
3.1 信号的经典统计特征
针对调相信号的特点,本文选取3个信号的经典统计特征:零中心归一化瞬时相位的平方均值、中心归一化瞬时相位的均方差和瞬时幅度包络均值.
零中心归一化瞬时相位平方的均值为
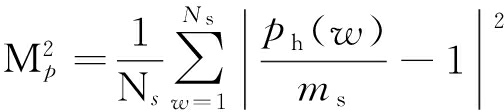
(3)
式中,Ns为总采样点数![]() 为瞬时相位ph(w)的均值.
为瞬时相位ph(w)的均值.
中心归一化瞬时相位的均方差为
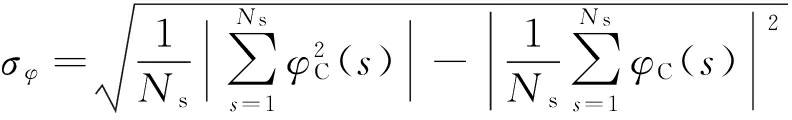
(4)
式中,![]() ,其中φ(s)为瞬时相位.
,其中φ(s)为瞬时相位.
瞬时幅度包络均值为
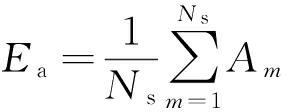
(5)
式中, Am为信号的瞬时幅度.
3.2 信号的高阶统计特征
信号的高阶统计特征是指信号的高阶矩、高阶累积量、高阶矩谱和高阶累积量谱这4种主要统计量.高斯随机过程的高阶累积量恒为零,故高阶累积量对高斯白噪声有着良好的抑制能力.对于一个具有零均值的复随机信号X(t),含有q项x*(t)的p阶混合矩可以表示为
Mpq=E[Xp-q(t)X*q(t)]
(6)
本文采用的高阶累积量可表示为
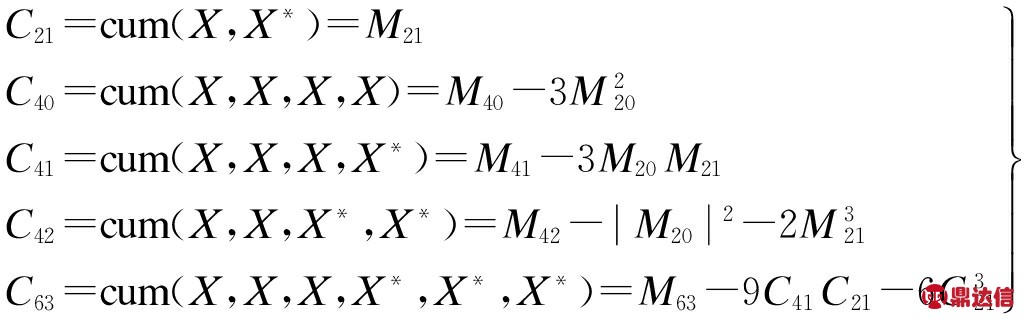
(7)
式中,cum()为累积量计算函数.
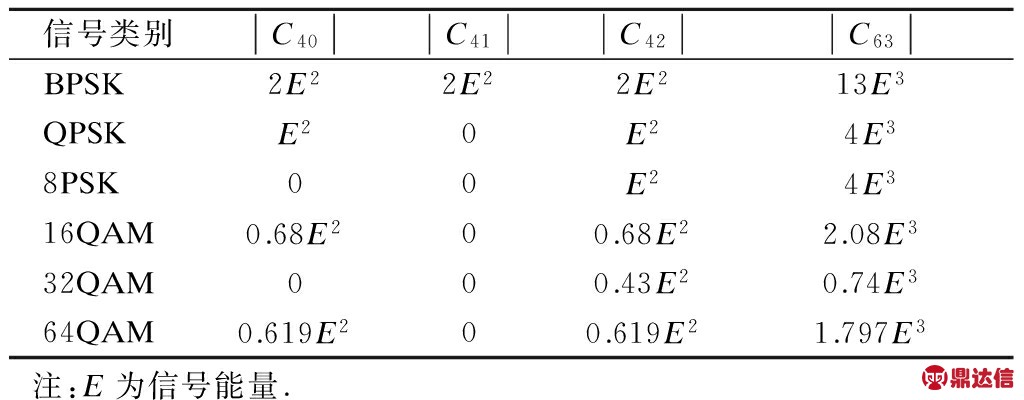
文献[6]对信号的高阶累积量理论值进行了推导和计算.表2列出了6种卫星常用调制信号高阶累积量的理论值.
为了抑制噪声和信号能量对特征的影响,结合文献[7]针对高级累积量的研究,并且考虑星上运算和处理能力,本文采用如下的高阶特征统计特征:
表2 PSK和QAM子类信号高阶累积量理论值
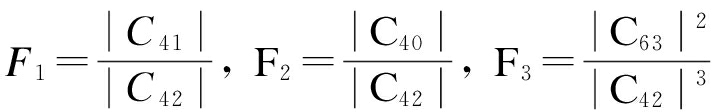
(8)
式中,F1和F2为区分MPSK子类信号的高阶统计特征;F3为区分MQAM子类信号的高阶统计特征.
4 基于信息熵改进的GSA算法优化的RBF网络
解决分类问题时,基函数中心的选择对RBFNN分类能力影响较大,而采用经典K均值聚类法选取基函数中心存在一定不足,因此本文采用基于信息熵改进的GSA算法(IEGSA)来优化RBFNN基函数的聚类中心,以提高RBF网络的分类和泛化能力.在解决RBF网络基函数中心的聚类优化问题时,第j个聚类的偏离误差为
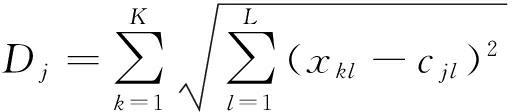
(9)
式中,cjl表示第j个聚类中心的第l个分量;xkl表示属于聚类Cj的实例Xk的第l个分量.
基于此,利用IEGSA优化RBFNN基函数中心时采用的适应度函数为
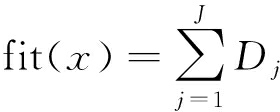
(10)
引力搜索算法是一种基于牛顿万有引力定律的启发式优化算法.为了进一步提高算法的全局寻优能力和收敛速度,文献[7]通过引入加速系数来平衡探索与开采的关系,使算法初期具有更广的全局搜索范围,后期具有更深的局部搜索能力并有一定几率跳出局部最优解.然而,加速系数是以算法迭代次数为依据来调节算法中粒子群进行探索和开采的,算法的迭代次数不能准确反映迭代过程中探索和开采关系.因此,本文引入粒子群的信息熵来反映算法迭代过程中粒子群的探索和开采,提出了基于信息熵改进的引力搜索算法(IEGSA).算法迭代过程中d维第i个粒子的信息熵为
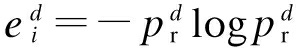
(11)
式中,![]() 表示对解空间进行划分后,粒子i在d维空间中某个子区间出现的概率.
表示对解空间进行划分后,粒子i在d维空间中某个子区间出现的概率.
算法迭代过程中粒子群的信息熵Ep为
(12)
式中,D为维度数;I为粒子数.
对于GSA算法,每次迭代执行过程中,计算算法平均解Sa和粒子群熵Epa的归一化值以及去趋势化粒子群熵Eqa和引力系数Ga的归一化值,可以得到其归一化值随算法迭代次数变化的曲线(见图2和图3).
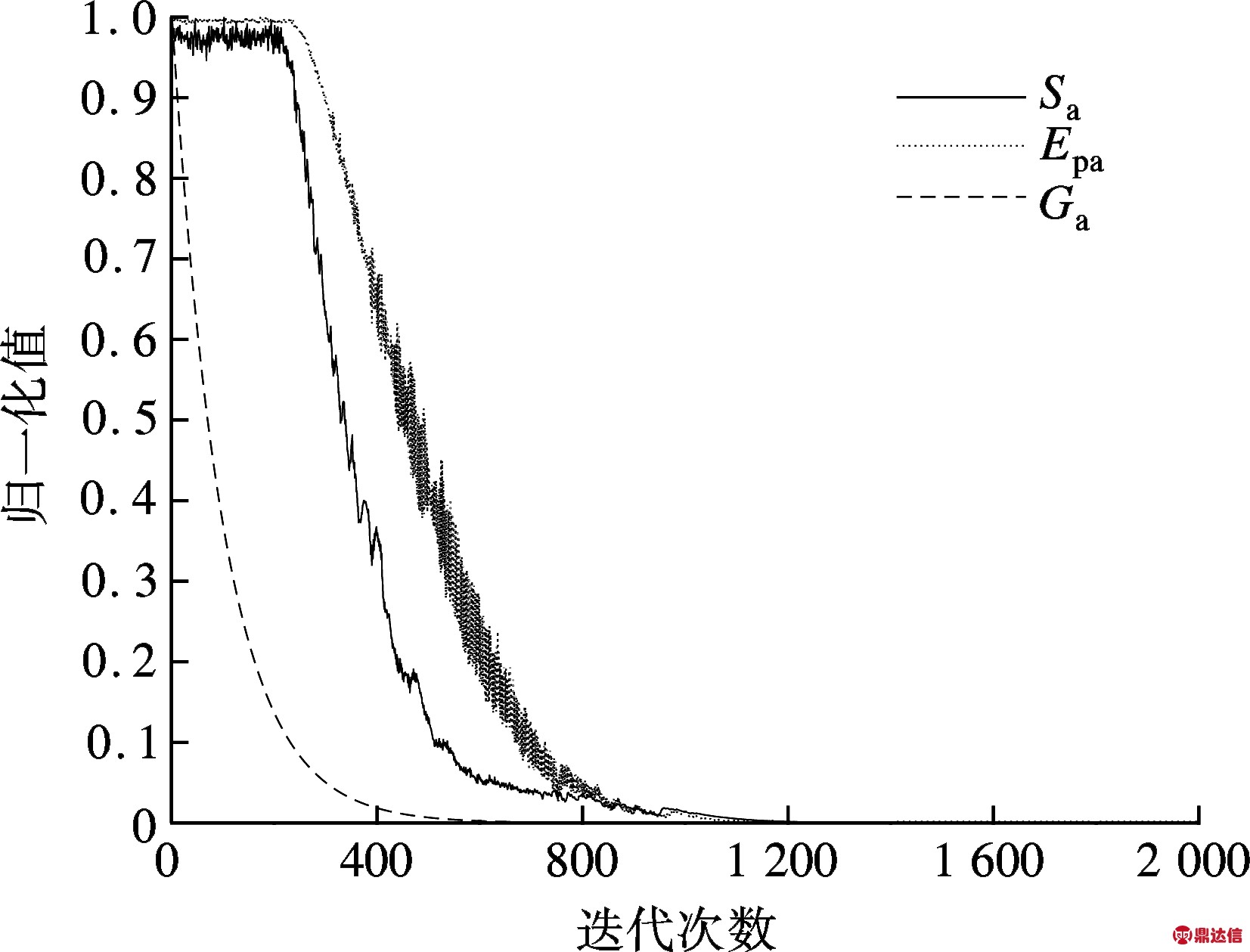
图2 归一化熵、平均解和引力系数的变化曲线
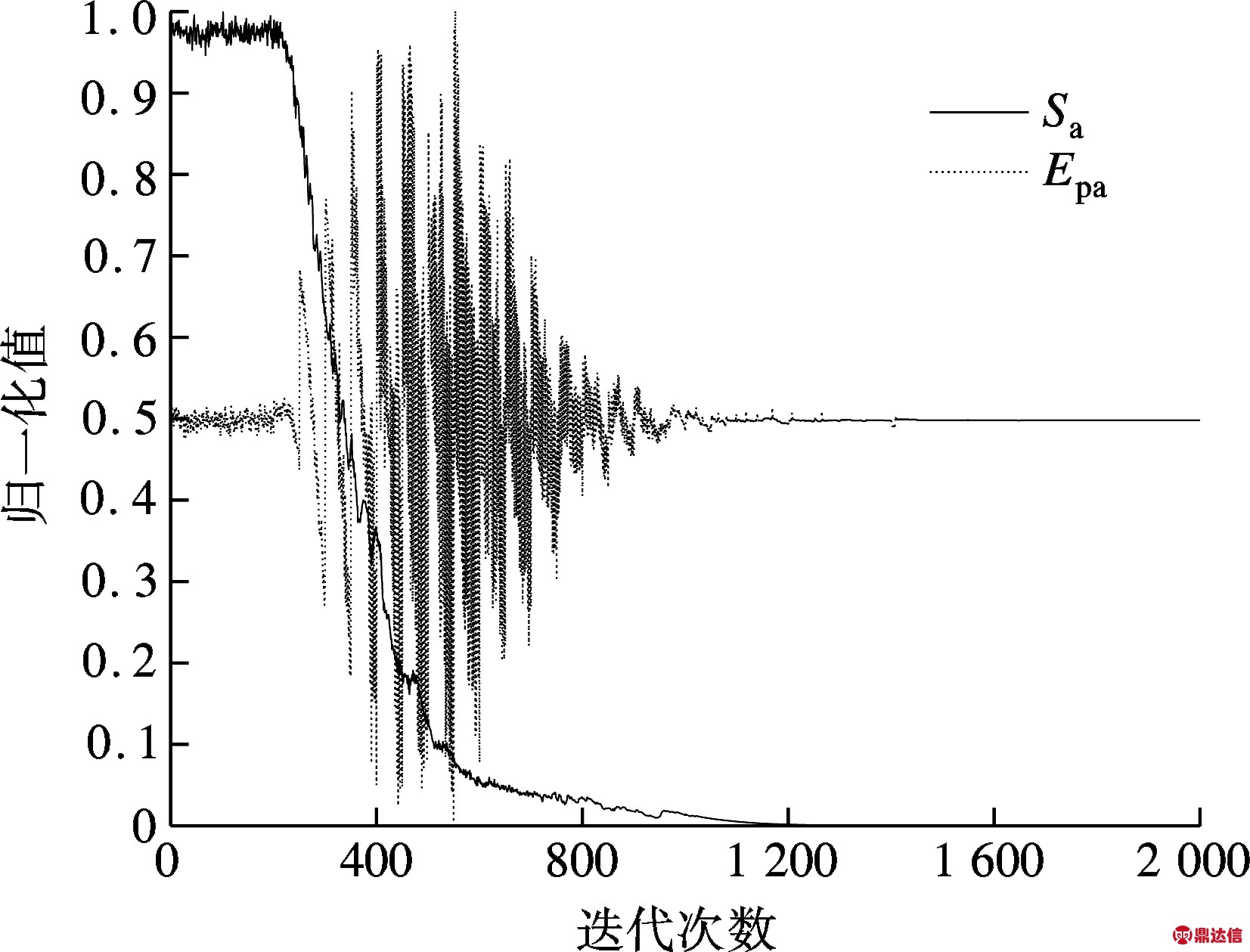
图3 归一化平均解与去趋势化熵的变化曲线
由图2所示,GSA算法迭代执行过程中粒子群的熵与算法平均解的归一化值变化曲线相似程度较高,故可以使用粒子群的熵来反映算法迭代过程中探索与开采的关系.结合图2与图3可以看出,粒子群熵的方差和数值变化对应算法迭代过程中3个阶段:① 初期随机搜索的粒子群熵较大,方差较小;② 中期定向搜索的粒子群熵开始减小,方差较大;③ 后期局部搜索的粒子群熵较小,方差也较小.结合粒子群算法中粒子群的速度更新公式,本文对原GSA算法中粒子的速度更新公式进行如下改进:
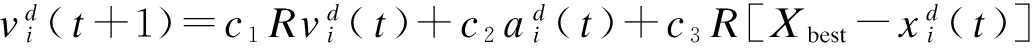
(13)
式中,![]() (t)分别为第i个粒子在d维中t时刻的速率、加速率和位置;R为[0,1]上均匀分布的随机数;Xbest为当前算法中粒子最优位置;c1,c2,c3为加权系数.
(t)分别为第i个粒子在d维中t时刻的速率、加速率和位置;R为[0,1]上均匀分布的随机数;Xbest为当前算法中粒子最优位置;c1,c2,c3为加权系数.
根据粒子群熵反映出的算法执行情况,在算法迭代执行过程中选择合适的加权系数,来调节算法探索和开采的关系.在初期,保证算法可以在足够大的空间中寻求最优解,增大随机搜寻的加权系数c1;中期保证算法尽可能快地向最优解收敛,增大加速度加权系数c2和全局最优的加权系数c3;后期允许算法跳出局部最优,随机地增大随机搜索的加权系数c1.
5 仿真结果
在仿真试验中,为了验证本文算法对卫星常用调相信号识别的有效性,选择了BPSK,QPSK,8PSK,16QAM,32QAM和64QAM六种卫星通信常用调相调制信号.6类信号样本的基本参数设置如下:载波频率为400 kHz,符号速率为100 KB/S,成型脉冲为升余弦脉冲,升余弦滚降系数为0.5,抽样点数为1 000.RBFNN参数设置如下:输入层节点数为6,隐藏层节点数为10,输出层节点数为3,随机生成初始连接矩阵,利用K均值聚类算法获取基函数初始中心.IEGSA参数设置如下:迭代次数为2 000,种群规模为100个,引力常数为200,引力改变系数为20.三个阶段的速度改变加权系数c1分别设置为1.5,0.5,1.5, c2分别设置为0.5,1,0.5, c3分别设置为0.5,1,0.5,梯度训练误差为0.001.
采用本文算法,在不同信噪比情况下得到的6种调相调制信号的识别率见图4.由图可知,在没有接收信号先验知识的情况下, 当信噪比高于1 dB
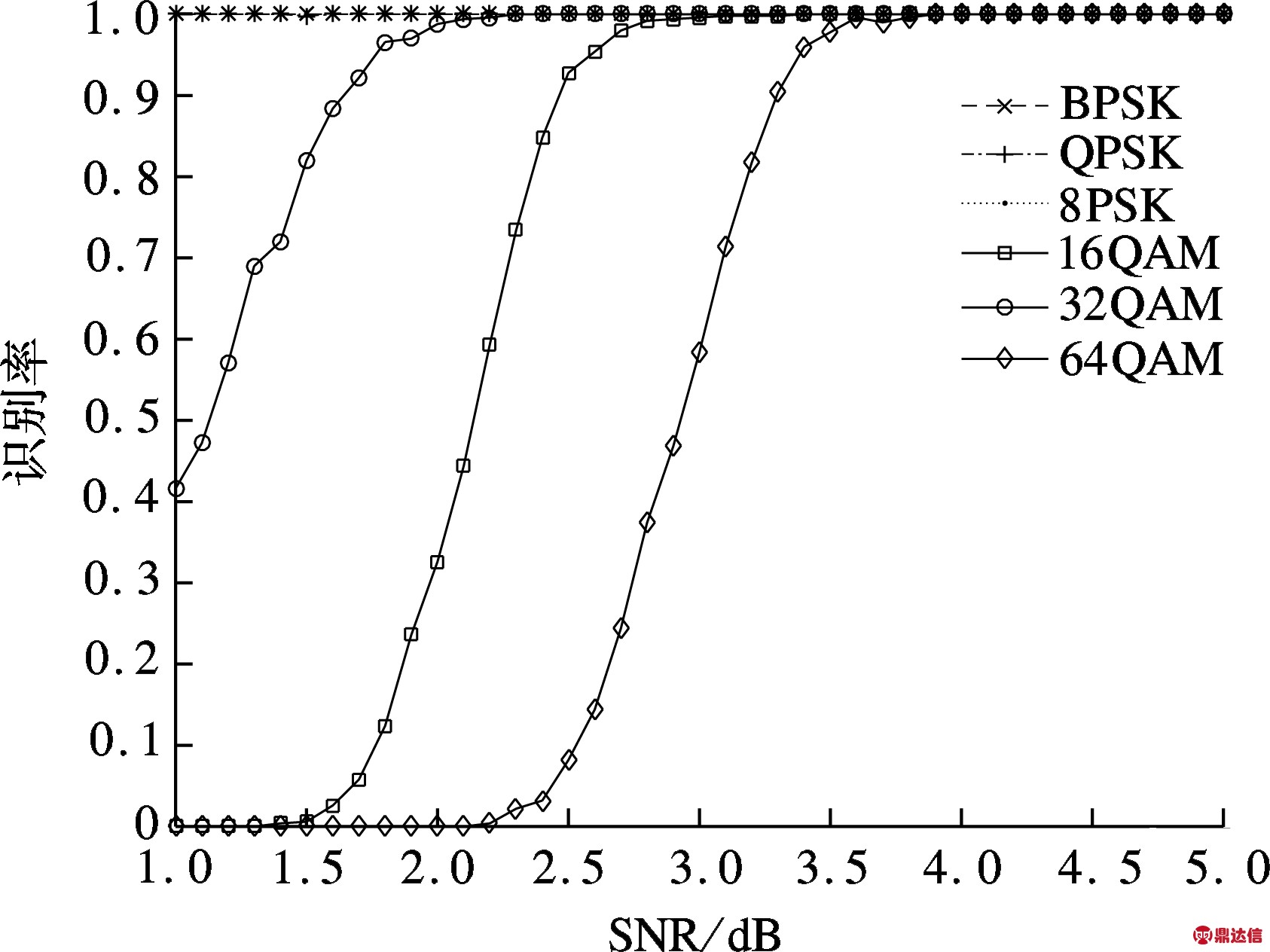
图4 本文算法在不同SNR下的识别率
时,本文算法对BPSK,QPSK和8PSK的识别率达到100%;当信噪比高于4 dB时,本文算法对调相调制信号BPSK,QPSK,8PSK,16QAM,32QAM和64QAM的识别率达到100%.
为了说明本文方法在低信噪比条件下的有效性,选取如下4种相关调制模式识别算法进行对比:① 以K均值聚类算法作为分类器的调制识别算法[7]; ② 基于高阶累积量和支持向量机的调制识别算法[8]; ③ 基于4阶累积量正交谱密度和决策分类树的调制识别算法[9]; ④ 基于高阶统计量和遗传算法的K近邻分类算法[10].这些算法所选用的信道模型均为AWGN信道.对于6种调制信号,本文算法与上述4种算法达到100%识别率时所需的最低SNR对比如图5所示.由图可知,本文算法在较低信噪比条件下就能实现对6种调制模式的100%识别率,尤其对于MQAM子类调制模式的识别率优势更为明显.
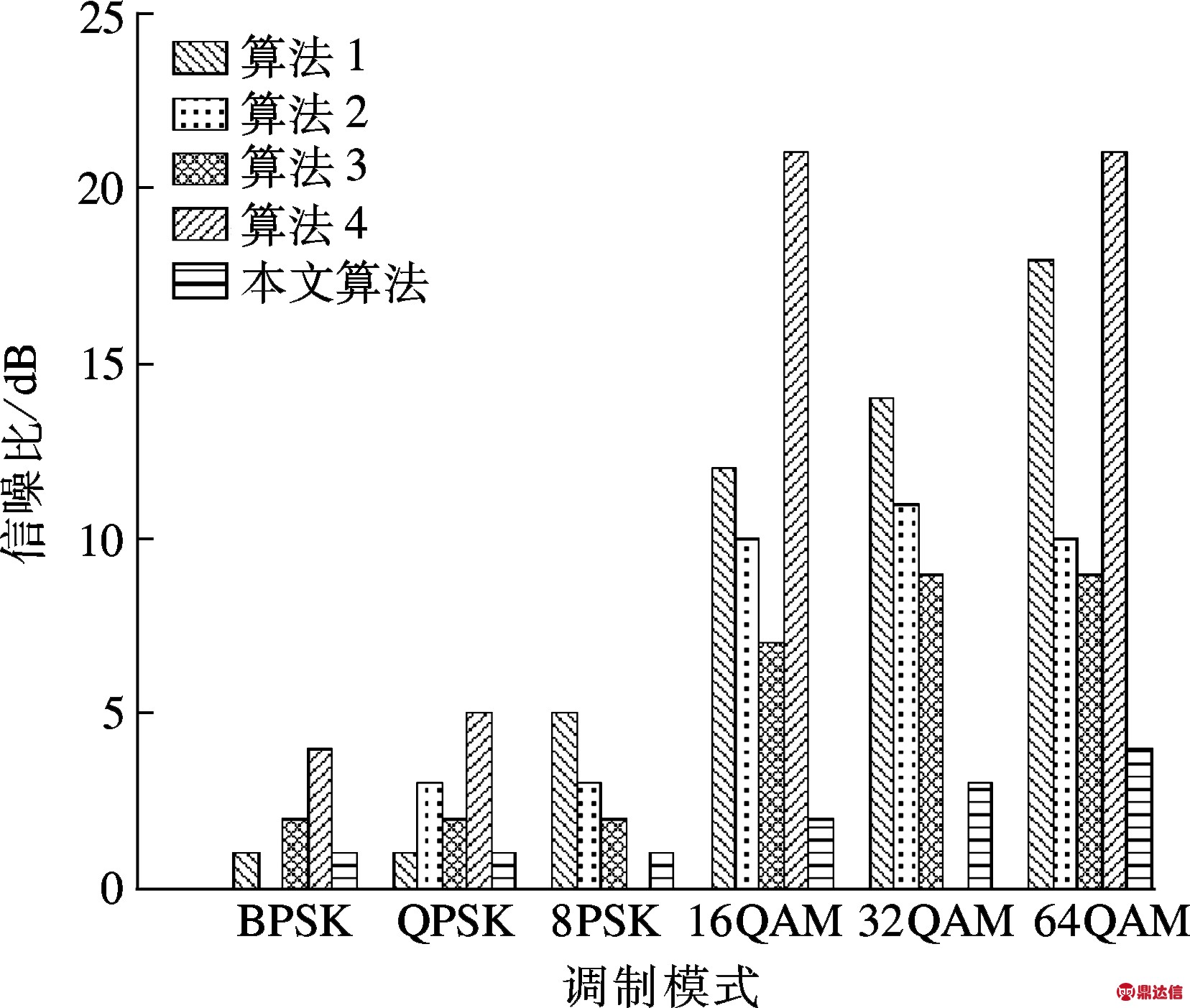
图5 不同算法达到100%识别率所需的最低SNR对比
6 结论
1) 本文提出了一种IEGSA优化的RBFNN调制识别算法.以信号的经典统计量和高阶统计量作为样本特征,基于IEGSA优化了RBF神经网络的分类和泛化能力.该算法对高斯白噪声不敏感,在较低信噪比和贫先验知识条件下仍具有较高的识别准确率.
2) 采用基于信息熵优化的GSA算法对基函数中心进行选择,引入粒子群的信息熵来调节算法执行过程中探索与开采的关系,进一步提高了RBF神经网络的分类和泛化能力.
3) 将IEGSA优化的RBFNN调制识别算法应用于调制模式自动识别中,可有效提高较低信噪比条件下的识别准确率,满足星载SDCA对物理层调制模式的识别需要,适合星上实际应用.


